1. Apa yang dimaksud supervised learning, unsupervised learning dan reinforcement learning? Berikan contoh masing-masing?
A. SUPERVISED LEARNING
Supervised learning merupakan suatu pembelajaran yang terawasi dimana jika output yang diharapkan telah diketahui sebelumnya. Biasanya pembelajaran ini dilakukan dengan menggunakan data yang telah ada. Pada metode ini, setiap pola yang diberikan kedalam jaringan saraf tiruan telah diketahui outputnya. Satu pola input akan diberikan ke satu neuron pada lapisan input. Pola ini akan dirambatkan di sepanjang jaringan syaraf hingga sampai ke neuron pada lapisan output. Lapisan output ini akan membangkitkan pola output yang nantinya akan dicocokkan dengan pola output targetnya. Nah, apabila terjadi perbedaan antara pola output hasil pembelajaran dengan pola output target, maka akan muncul error. Dan apabila nilai error ini masih cukup besar, itu berarti masih perlu dilakukan pembelajaran yang lebih lanjut. Contoh algoritma jaringan saraf tiruan yang mernggunakan metode supervised learning adalah hebbian (hebb rule), perceptron, adaline, boltzman, hapfield, dan backpropagation.
Pada kesempatan ini saya akan membahas tentang metode hebb rule dan perceptron.
v Hebb rule merupakan metode pembelajaran dalam supervised yang paling sederhana, karena pada metoode ini pembelajaran dilakukan dengan cara memperbaiki nilai bobot sedemikian rupa sehingga jika ada 2 neuron yang terhubung, dan keduanya pada kondisi hidup (on) pada saat yang sama, maka bobot antara kedua dinaikkan. Apabila data dipresentasiakn secara bipolar, maka perbaikan bobotnya adalah
wi(baru)=wi(lama)+xi*y
Keterangan:
wi : bobot data input ke-i;
xi : input data ke-i;
y : output data.
Misalkan kita menggunakan pasangan vektor input (s) dan vektor output sebagai pasangan vektor yang akan dilatih. Sedangkan vektor yang hendak digunakan sebagai testing adalah vektor (x).
Algoritma pasangan vektor diatas adalah sebagai berikut:
0. Insialisasi semua bobot dimana:
wij=0;
i =1,2……n;
j =1,2…..m
1. Pada pasangan input-output(s-t), maka terlebih dahulu dilakukan langkah-langkah sebagai berikut:
a. Set input dengan nilai yang sama dengan vektor inputnya:
xi=si; (i=1,2……,n)
b. Set outputnya dengan nilai yang sam dengan vektor outputnya:
yj=tj; (j=1,2,…..,m)
c. Kemudian jika terjadi kesalahan maka perbaiki bobotnya:
wij(baru)=wij(lama)+xi*yj;
(i=1,2,….,n dan j=1,2,….,m)
sebagai catatan bahwa nilai bias selalu 1.
Contoh:
Sebagaimana yang kita ketahui dalam fungsi OR jika A & B= 0 maka “OR” 0, tetapi jika salah satunya adalah 1 maka “OR” 1, atau dengan kata lain jika angkanya berbeda maka hasilnya 1. Misalkan kita ingin membuat jaringan syaraf untuk melakukan pembelajaran terhadap fungsi OR dengan input dan target bipolar sebagai berikut:
Input Bias Target
-1 -1 1 -1
-1 1 1 1
1 -1 1 1
1 1 1 1
X= T= Bobot awal=
-1 -1 -1 w=
-1 1 1 0
1 -1 1 0
1 1 1 b=0
(catatan penting: bobot awal dan bobot bias kita set=0)
Data ke-1
w1 = 0+1=1
w2 =0+1=1
b =0-1=-1
Data ke-2
w1 = 1-1=0
w2 =1+1=2
b =0+1=1
Data ke-3
w1 = 0+1=1
w2 =2-1=1
b =0+1=1
Data ke-4
w1 = 1+1=2
w2 =1+1=2
b =1+1=2
Kita melakukan pengetesan terhadap salah satu data yang ada, misal kita ambil x=[-1-1] dan kita masukkan pada data ke-4 maka hasilnya adalah sebagai berikut:
y=2+(-1*2)+(-1*2)=-2
karena nilai yin=-2, maka y=f(yin)=f(-2)=-1 (cocok dengan output yang diberikan)
Perceptron merupakan salah satu bentuk jaringan syaraf tiruan yang sederhana. Perceptron biasanya digunakan untuk mengklasifikasikan suatu tipe pola tertentu yang sering dikenal dengan pemisahan secara linear. Pada dasarnya, perceptron pada jaringan syaraf dengan satu lapisan memiliki bobot yang bisa diatur dan suatu nilai ambang(thershold). Algoritma yang digunakan oleh aturan perceptron ini akan mengatur parameter-parameter bebasnya melalui proses pembelajaran. Nilai thershold( pada fungsi aktivasi adalah non negatif. Fungsi aktivasi ini dibuat sedemikian rupa sehingga terjadi pembatasan antara daerah positif dan daerah negatif.
Garis pemisah antara daerah positif dan daerah nol memiliki pertidaksamaan yaitu:
w1x1+ w2x2+b >
Sedangkan garis pemisah antara daerah negatif dengan daerah nol memiliki pertidaksamaan:
w1x1+ w2x2+b < –
Misalkan kita gunakan pasangan vektor input (s) dan vektor output (t) sebagai pasangan vektor yang akan dilatih.
Algoritmanya adalah:
0. Inisialisasi semua bobot dan bias:
(agar penyelesaiannya jadi lebih sederhana maka kita set semua bobot dan bias sama dengan nol).
Set learning rate( ): (0< 1).
1. Selama kondisi berhenti bernilai false. Lakukan langkah-langkah sebagai berikut:
(i) Untuk setiap pasangan pembelajaran s-t, maka:
a. Set input dengan nilai sama dengan vektor input:
xi=si;
b. Hitung respon untuk unit output:
yin=b+y-
c. Perbaiki bobot dan bias jika terjadi error:
jika y≠t maka:
wi(baru)=wi(lama)+
b(baru)=b(lama)+
jika tidak, maka:
wi(baru)= wi(lama)
b(baru)=b(lama)
Selanjutnya lakukan tes kondisi berhenti: jika tidak terjadi perubahan pada bobot pada (i) maka kondisi berhenti adalah TRUE, namun jika masih terjadi perubahan pada kondisi berhenti maka FALSE.
Nah, algoritma seperti diatas dapat digunakan baik untuk input biner maupun bipolar, dengan tertentu, dan bias yang dapat diatur. Pada algoritma tersebut bobot-bobot yang diperbaiki hanyalah bobot-bobot yang berhubungan dengan input yang aktif (xi≠0) dan bobot-bobot yang tidak menghasilkan nilai y yang benar.
Sebagai contoh, misalkan kita ingin membuat jaringan syaraf yang melakukan pembelajaran terhadap fungsi AND dengan input biner dan target bipolar sebagai berikut:
Input Bias Target
1 1 1 1
1 0 1 -1
0 1 1 -1
0 0 1 -1
Bobot awal : w=[0,0 0,0]
Bobot bias awal : b=[0,0]
Learning rate( ) : 0,8
Thershold(tetha) : 0,5
Epoh ke-1(siklus perubahan bobot ke-1)
Data ke-1
yin=0,0+0,0+0,0=0,0
Hasil aktivasi= 0(-0,5 < yin < 0,5)
Target = 1
Bobot baru yang diperoleh:
w1= 0,0+0,8*1,0*1,0=0,8
w2= 0,0+0,8*1,0*1,0=0,8
Maka bobot bias barunya:
b= 0,8+0,8*-1,0=0,8
Data ke-2
yin=0,8+0,8+0,0=1,6
Hasil aktivasi= 1(yin > 0,5)
Target = -1
Bobot baru yang diperoleh:
w1= 0,8+0,8*-1,0*1,0=0,8
w2= 0,8+0,8*-1,0*1,0=0,0
Maka bobot bias barunya:
b= 0,8+0,8*-1,0=0,0
Data ke-3
yin=0,0+0,0+0,8=0,8
Hasil aktivasi= 1( yin > 0,5)
Target = -1
Bobot baru yang diperoleh:
w1= 0,0+0,8*1,0*0,0=0,0
w2= 0,8+0,8*-1,0*1,0=0,8
Maka bobot bias barunya:
b= 0,0+0,8*-1,0=-0,8
Data ke-4
yin=-0,8+0,0+0,0=-0,8
Hasil aktivasi= -1( yin < – 0,5)
Target = -1
Epoh ke-10(siklus perubahan bobot ke-10)
Data ke-1
yin=-3,2+1,6+2,4=0,8
Hasil aktivasi=-1(yin >0,5)
Target = 1
Data ke-2
yin=-3,2+1,6+0,0=-1,6
Hasil aktivasi=-1(yin <-0,5)
Target = -1
Data ke-3
yin=-3,2+0,0+2,4=-0,8
Hasil aktivasi=-1(yin <-0,5)
Target = -1
Data ke-4
yin=-3,2+0,0+0,0=-3,2
Hasil aktivasi=-1(yin <-0,5)
Target = -1
Siklus perubahan setiap bobot tersebut terus diulangi sampai tidak terjadi perubahan bobot lagi. Nah pada algoritma ini perubahan bobot(epoh) sudah tidak terjadi pada langkah ke-10 sehingga pembelajaran dihentikan. Dan hasil yang diperoleh adalah:
Nilai bobot(w1)=1,6
Nilai bobot(w2)=2,4
Bobot bias(b) =-3,2.
Dengan demikian garis yang membatasi daerah positif dan daerah nol memenuhi pertidaksamaan:
1,6×1+2,4×2-3,2 > 0,5
Sedangkan garuis yang membatasi antara daerah negatif dan daerah nolnya memenuhi pertidaksamaan:
1,6×1+2,4×2-3,2 < – 0,5
Contoh : LVQ(Learning Vector Quantization), neocognitron
B. UNSUPERVISED LEARNING
Unsupervised learning merupakan pembelajan yang tidak terawasi dimana tidak memerlukan target output. Pada metode ini tidak dapat ditentukan hasil seperti apa yang diharapkan selama proses pembelajaran, nilai bobot yang disusun dalam proses range tertentu tergantung pada nilai output yang diberikan. Tujuan metode uinsupervised learning ini agar kita dapat mengelompokkan unit-unit yang hampir sama dalam satu area tertentu. Pembelajaran ini biasanya sangat cocok untuk klasifikasi pola. Contoh algoritma jaringan saraf tiruan yang menggunakan metode unsupervised ini adalah competitive, hebbian, kohonen, LVQ(Learning Vector Quantization), neocognitron.
Pada kali ini saya akan membahas tentang metode kohonen. Jaringan syaraf self organizing, yang sering disebut juga topology preserving maps, yang mengansumsikan sebuah struktur topologi antar unit-unit cluster. Jaringan syaraf self organizing ini pertama kali diperkenalkan oleh Tuevo Kohonen dari University of Helsinki pada tahun 1981. Jaringan kohonen SOM(Self Organizing Map) merupakan salah satu model jaringan syaraf yang menggunakan metode pembelajaran unsupervised. Jaringan kohonen SOM terdiri dari 2 lapisan(layer), yaitu lapisan input dan lapisan output. Setiap neuron dalalm lapisan input terhubung dengan setiap neuron pada lapisan output. Setiap neuron dalam lapisan output merepresentasikan kelas dari input yang diberikan.
Penulisan istilah yang ada pada struktur jaringan kohonen Self Organizing Map adalah sebagai berikut:
X : vektor input pembelajaran.
X=(x1, x2,…, xj,…..,xn)
: learning rate
: radius neighborhood
X1 : neuron/node input
w0j : bias pada neuron output ke-j
Yj : neuron/node output ke-j
C : konstanta
Berikut ini adalah tahapan Algoritma dari kohonen self organizing map adalah sebagai berikut :
Langkah 1. Inisialisasikan bobot wij. Set parameter-parameter tetangga dan set parameter learning rate.
Langkah 2. Selama kondisi berhenti masih bernilai salah, kerjakan langkah-langkah berikut ini :
a. Untuk masing-masing vektor input x, lakukan :
Titik Pusat
(0,0) x,y
b. Untuk masing-masing j, lakukan perhitungan :
D(j)= )
c. Tentukan J sampai D( j) bernilai minimum.
d. Untuk masing-masing unit j dengan spesifikasi tetangga tertentu pada j dan untuk semua I, kerjakan :
wij(baru)=(wij)lama+ [xi –wij( lama)]
e. Perbaiki learning rate ( )
f. Kurangi radius tetangga pada waktu-waktu tertentu.
g. Tes kondisi berhenti.
Sebagai contohnya, data yang digunakan adalah penelitian berupa realisasi penerimaan keuangan daerah tingkat II suatu propinsi serta jumlah penduduk pertengahan tahunnya dalam sebuah kabupaten/kota. Atribut-atribut yang digunakan dalam penelitian ini adalah:
a. X1 = Jumlah penduduk
b. Pendapatan Daerah Sendiri(PDS) yang terdiri dari:
1. Pendapatan Asli Daerah(PDA) yang berupa:
ü X2 = Pajak Daerah
ü X3 = Retribusi Daerah
ü X4 = Bagian laba usaha daerah
ü X4 = Penerimaan lain-lain
2. Bagian pendapatan dari pemerintah dan instansi yang lebih tinggi yang berupa:
ü X6 = Bagi hasil pajak
ü X7 = Bagi hasil bukan pajak
ü X8 = Subsidi daerah otonom
ü X9 = Bantuan pembangunan
ü X10= Penerimaan lainnya
3. Pinjaman pemerintah daerah
ü X11= Pinjaman Pemerintah Pusat
ü X12= Pinjaman Lembaga Keuangan Dalam Negeri
ü X13= Pinjaman Dari Luar Negeri
Data set yang digunakan sebagai input tersebut dinormalkan dengan nilai rata-rata sebagai acuan yang analog dengan persamaan:
f(x)-
Berdasarkan data yang tesebut maka akan terlihat untuk masing-masing atribut memiliki nilai terendah, nilai tertinggi, dan nilai rata-rata. Selanjutnya dari nilai rata-rata tersebut maka akan menjadi acuan untuk menentukan input dari data menuju ke input pada jaringan saraf tiruan kohonen dengan pengkodean 1 dan 0. Kemudian data-data input tersebut akan diproses oleh JST sehingga menghasilkan output berupa kelompok daerah tingkat II berdasarkan penerimaan daerah. Jaringan kohonen SOM ini akan menghubungkan antara neuron input dan neuron output dengan koneksi bobot, yang mana bobot ini selalu diperbaiki pada proses iterasi pelatihan jaringan. Kemudian aliran informasi system JST ini akan mengelompokan tingkat kesejahteraan daerah tingkat II, diawali dengan dimasukkannya data penerimaan daerah. Data-data inilah yang akan berfungsi sebagai input awal selain parameter input berupa learning rate( ), dan radius neighborhood(R).
Contoh : competitive learning
Reinforcement Learning
Reinforcement Learning (RL) adalah pembelajaran (learning) terhadap apa yang akan dilakukan (bagaimana memetakan situasi kedalam aksi) untuk memaksimalkan reward. Pembelajar (learner) tidak diberitahu aksi mana yang akan diambil, tetapi lebih pada menemukan aksi mana yang dapat memberikan reward yang maksimal dengan mencobanya. Aksi tidak hanya mempengaruhi reward langsung, tetapi juga situasi berikutnya, begitu juga semua reward berikutnya. Dua karekteristik inilah (pencarian trial-error dan reward tertunda) yang membedakan RL dengan yang lain.
Agen harus mampu untuk mengindera (sense) keadaan (state) lingkungan luas dan harus dapat mengambil aksi yang mempengaruhi state.
RL berbeda dengan pembelajaran terawasi (Supervised learning ). Pembelajaran terawasi merupakan pembelajaran dari contoh-contoh yang disediakan oleh pengawas luar yang berpengetahuan. Hal ini sangat penting dalam pembelajaran, tapi itu sendiri tidak cukup untuk belajar dari sebuah interaksi. Dalam permasalahan interaksi, hampir tidak mungkin secara praktis mendapatkan contoh dari perilaku yang diinginkan baik yang benar dan mewakili semua situasi dimana agen harus beraksi. Karena itu agen harus belajar dari pengalamannya.
Salah satu tantangan yang muncul dalam RL dan tidak terdapat pada jenis pembelajaran lain adalah eksplorasi dan eksploitasi. Untuk mendapatkan banyak reward, agen RL lebih mementingkan aksi yang telah dicoba waktu lalu dan terbukti efektif menghasilkan reward. Tapi untuk menemukan aksi tersebut, harus mencoba aksi yang belum pernah terpilih sebelumnya. Agen harus mengeksplotasi apa yang telah diketahui untuk mendapatkan reward, tetapi juga harus mengkeksplorasi untuk membuat pemilihan aksi yang lebih baik kedepannya.
2. Apa yang dimaksud dengan Learning Decision Tree dan berikan contohnya?
Secara konsep Decision tree adalah salah satu dari teknik decision analysis.Tries sendiri pertama kali diperkenalkan pada tahun 1960-an oleh Fredkin. Trie atau digital tree berasal dari kata retrival (pengambilan kembali) sesuai dengan fungsinya. Secara etimologi kata ini diucapkan sebagai ‘tree’. Meskipun mirip dengan penggunaan kata ‘try’ tetapi hal ini bertujuan untuk membedakannya dari general tree. Dalam ilmu komputer, trie, atau prefix tree adalah sebuah struktur data dengan representasi ordered tree yang digunakan untuk menyimpan associative array yang berupa string. Berbeda dengan binary search tree (BST) yang tidak ada node di tree yang menyimpan elemen yang berhubungan dengan node sebelumnya dan, posisi setiap elemen di tree sangat menentukan. Semua keturunan dari suatu node mempunyai prefix string yang mengandung elemen dari node itu, dengan root merupakan string kosong. Values biasanya tidak terkandung di setiap node, hanya di daun dan beberapa node di tengah yang cocok dengan elemen tertentu.
Secara singkat bahwa Decision Tree merupakan salah satu metode klasifikasi pada Text Mining. Klasifikasi adalah proses menemukan kumpulan pola atau fungsi-fungsi yang mendeskripsikan dan memisahkan kelas data satu dengan lainnya, untuk dapat digunakan untuk memprediksi data yang belum memiliki kelas data tertentu (Jianwei Han, 2001).
Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah Decision Tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision Tree melakukan strategi pencarian secara top-down untuk solusinya. Pada proses mengklasifikasi data yang tidak diketahui, nilai atribut akan diuji dengan cara melacak jalur dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data baru tertentu.
Decision Tree menggunakan algoritma ID3 atau C4.5, yang diperkenalkan dan dikembangkan pertama kali oleh Quinlan yang merupakan singkatan dari Iterative Dichotomiser 3 atau Induction of Decision “3″ (baca: Tree).
Algoritma ID3 membentuk pohon keputusan dengan metode divide-and-conquer data secara rekursif dari atas ke bawah. Strategi pembentukan Decision Tree dengan algoritma ID3 adalah:
• Pohon dimulai sebagai node tunggal (akar/root) yang merepresentasikan semua data..
• Sesudah node root dibentuk, maka data pada node akar akan diukur dengan information gain untuk dipilih atribut mana yang akan dijadikan atribut pembaginya.
• Sebuah cabang dibentuk dari atribut yang dipilih menjadi pembagi dan data akan didistribusikan ke dalam cabang masing-masing.
• Algoritma ini akan terus menggunakan proses yang sama atau bersifat rekursif untuk dapat membentuk sebuah Decision Tree. Ketika sebuah atribut telah dipilih menjadi node pembagi atau cabang, maka atribut tersebut tidak diikutkan lagi dalam penghitungan nilai information gain.
• Proses pembagian rekursif akan berhenti jika salah satu dari kondisi dibawah ini terpenuhi:
1. Semua data dari anak cabang telah termasuk dalam kelas yang sama.
2. Semua atribut telah dipakai, tetapi masih tersisa data dalam kelas yang berbeda. Dalam kasus ini, diambil data yang mewakili kelas yang terbanyak untuk menjadi label kelas pada node daun.
3. Tidak terdapat data pada anak cabang yang baru. Dalam kasus ini, node daun akan dipilih pada cabang sebelumnya dan diambil data yang mewakili kelas terbanyak untuk dijadikan label kelas.
Beberapa contoh pemakaian Decision Tree,yaitu :
• Diagnosa penyakit tertentu, seperti hipertensi, kanker, stroke dan lain-lain
• Pemilihan produk seperti rumah, kendaraan, komputerdanlain-lain
• Pemilihan pegawai teladan sesuai dengan kriteria tertentu
• Deteksi gangguan pada computer atau jaringan computer seperti Deteksi Entrusi, deteksi virus (Trojan dan varians)
Referensi :
Back Link to : www.binus.ac.id
Back Link to : www.binusmaya.ac.id
 , where
, where 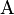 ,
, 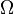 ,
, 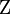 ,
,  are defined as follows:
are defined as follows: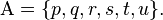
 ,
, 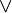 , and
, and 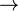 ), one can be taken as primitive and the other two can be defined in terms of it and negation (
), one can be taken as primitive and the other two can be defined in terms of it and negation ( ).
).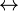 ) can of course be defined in terms of conjunction and implication, with
) can of course be defined in terms of conjunction and implication, with  defined as
defined as  .
. partition as follows:
partition as follows:

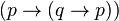


 and
and  , infer
, infer  ). Then
). Then  is defined as
is defined as 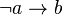 , and
, and 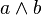 is defined as
is defined as 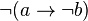 .
.